Principles and Practice of Database Systems
数据库系统课程复习,适用于阿伯丁大学 JC2504 课程
1 Database & database users
1.1 Definitions
- Data: 原始的、未经组织的事实和数字
- Information: 对数据进行了上下文化、分类、计算和浓缩处理之后得到的结果
- Knowledge: 通过经验、洞察力、理解以及将信息放入具体情境中而获得的深入认识
例如,在一项市场调查中,收集来自问卷调查的原始回复即为“数据”。将这些回复按照年龄段、消费偏好等因素分类并计算出不同群体的购买倾向,则转化为了有用的“信息”。最终,通过分析这些信息并结合行业趋势和历史销售记录等因素来预测未来市场变化或制定营销策略,则达到了更高阶层次的“知识”。
1.2 What is a database
- Database (DB): 被描述为数据集合或相关数据的存储库
- Database management system (DBMS): 是一种软件,用于管理和控制对数据库的访问。它允许用户创建、查询、更新和管理数据库
- Database application (DA): 指与数据库交互以执行特定任务的程序。例如使用SQL语言编写查询来检索或修改数据
- Database system: “Database system = DAs + DBMS + DB”。意味着一个完整的数据库环境包括应用程序、管理系统以及数据本身
1.3 Four main types of actions involve databases (DCMS)
- Defining: 它包括必须存储在数据库中的数据的数据类型、结构和约束。数据库描述信息也由DBMS以数据库目录或字典的形式存储;它被称为元数据
- Constructing: 它是将数据存储在由DBMS维护的某种存储介质上的过程
- Manipulating: 它包括使用查询来检索数据库,更新数据库以反映系统的变化,以及从数据生成报告等功能
- Sharing: 允许多个用户和程序同时访问数据库
1.4 Responsibilities of the database administrator and the database designer
- Database administer —— work with database software
- find ways to store, organise and manage data
- keep database up-to-date
- manage database access
- trouble shooting 故障排除
- designing maintenance procedures and putting them into operation 设计维护程序并实施
- database designer
- defining the detailed database design, including tables, indexes, views, constraints, triggers, stored procedures and other database-specific constructs needed to store, retrieve and delete persistent objects 定义详细的数据库设计,包括表、索引、视图、约束、触发器、存储过程以及存储、检索和删除持久对象所需的其他特定于数据库的构造
1.5 Four main characteristics of the database approach
- self-describing nature of a database system 数据库系统自描述性质
- insulation between programs and data 程序与数据之间的绝缘
- data abstraction 数据抽象
- support of multiple views of the data 支持数据的多个视图
例如,在一个大学数据库中,学生可能只能查看他们自己课程和成绩相关信息(支持多重视图),而不需要关心后台如何处理或存储这些信息(程序与数据隔离)。同时,所有课程和成绩信息被保存在统一格式下(自描述本质),且学生通过网页或应用访问时所见是经过优化处理显示给最终用户(比如表格形式)的结果,隐藏了复杂查询过程(数据抽象)
2 SQL
2.1 SQL - Structured Query Language
- Structured programming?
- NO! - Structured English (from ‘SEQUEL’)
- It’s a declarative language - says what, not how
- It’s an abstract & portable interface to RDBMSs 抽象和可移植接口
例如,如果你想从一个名为“employees”的表中检索所有员工信息,你可以使用如下SQL命令: sql SELECT * FROM employees; 这条命令会返回该表中所有员工的记录,并且无论底层数据库管理系统是Oracle、MySQL还是其他系统,这条命令基本上都保持不变。因此,“抽象且可移植”在这里意味着SQL为用户隐藏了与特定数据库交互所需处理的复杂性和差异性。
- SQL uses English keywords & user-defined names
- SELECT belongs to DML
- SELECT retrieves & displays data from the database 检索和显示
2.2 SQL Components: DDL, DCL & DML
Three main categorues (or sub-languages) of SQL:
- Data definition language (DDL) for creating a DB:
- e.g., CREATE, DROP, ALTER
- Data control language (DCL) for administering a DB:
- e.g., GRANT, DENY, USE
- Data manipulating language (DML) to access a DB:
- e.g., SELECT, INSERT, UPDATE, DELETE
2.3 SQL Aggregate Functions 聚合函数
- we do not want to just reterive data 我们不止想要检索数据
- we also want to summarise data 我们同样也想总结数据
- aggregate functions compute summarization (or aggregation) of data 聚合函数帮我们计算数据的汇总(或聚合)
Aggregate Functions:
2.4 Set Operations in SQL 集合操作
Syntax
- (SELECT …) UNION (SELECT …)
- (SELECT …) INTERSECT (SELECT …)
- (SELECT …) EXCEPT (SELECT …)
Some DBMSs use MINUS instead of EXCEPT
For set operations, the tables must be union-compatible 对于集合操作,表必须是联合兼容的
- i.e., 拥有相同数量和类型的列
2.5(Q) Three differences between a database schema and a database state
- A database schema represents the overall design of the database. In contrast, the database state represents the current state of data in the database.
database schema 表示数据库的总体设计,相反,database stata 表示数据库中数据的当前状态
- The database schema is changed occasionally. In contrast, the database state is changed frequently.
database schema 偶尔更改,相反,database stata 经常更改
- Initially when defining a database, only the database schema is specified. The database state is the empty state when the database is defined.
最初定义数据库时,只明确 database schema,而 database state 是定义数据库时的空状态
2.6(Q) The reasons for logical data independence is harder to achieve compared to physical data independence 逻辑数据独立性比物理数据独立性更难实现的原因
- Logical data independence is harder to achieve as the application programs are heavily dependent on the logical format of the data they access
应用程序严重依赖它们访问的数据的逻辑格式
- Hence, a change at the conceptual level might require changing the entire program application
概念层面上做出改变可能需要修改整个程序应用
- When it comes to physical data independence, a change in the location of the database or modifying the file organisation or use of new storage devices will not require change at the higher logical levels
在物理数据独立性方面,改变数据库位置或修改文件组织结构、使用新的存储设备,并不会要求在更高的逻辑层次上进行改变
解释与例子:
- 逻辑数据独立性指在不改变应用程序的情况下能够更改数据库中表和字段(即数据模型)
- 例如,一个账单系统软件依赖特定格式来读取用户信息;如果把“全名”一栏拆成“姓”和“名”,可能需要对软件代码进行大量修改
- 物理数据独立性是指在不影响到数据库在概念或者视图层面时可以更换底层存储设施或者文件系统
- 比如说,将数据库从硬盘迁移到SSD存储器,并不需要对查询语句等代码作出任何调整
3 Relational Model (逻辑数据模型)
3.1 Database Design
- Process of fitting a database solution to client’s requirements 使数据库解决方案符合用户的要求
- Client’s requirements will never be mathematically ‘crisp’ 客户的要求永远不可能在数学上“清晰”
- So, not possible to fit a unique solution mathematically 所以不可能只有一种独特的解决方案
- Our approach
- use semi-formal methods to arrive at an initial design 使用半形式化方法达到初步设计
- use iterative(迭代) refinement(优化) to improve the design 使用迭代优化来改进设计
- Design process is subjective and creative 一千个人有一千个哈姆雷特
3.2 Phases of database design
- DB design achieved in three phases:
- Conceptual
- Logical
- Physical
- 在简单的领域,我们可能不会使用三层面方法
3.3 ER Modelling (概念数据模型)
- models a domian of discourse
- central ideas
- domians are made up of entities
- relationships link associated Entities
- Entities and relationships have properties called attributes 实体和关系有被称为“属性”的组成部分
- Certain attributes are special, call them primary keys and alternate keys
- Need integrity constraints to preserve domain consistency
- Deliverables 可交付成果
- ER Models - documented diagrammatically
- Data dictionary
- Documentation is an important component of ER modelling
3.4(Q) The difference between an attribute and a value set
- Attributes describe the instances in the row of a database 属性描述数据库行中的实例
- e.s., attributes in an invoice can be price, invoice number and date
- A value set specifies the set of values that may be assigned to that attribute for each individual entity 一个值集指定了一组值,这些值可以分配给每个单独实体的属性
4 Enhanced Entity-Relationship Model (EER)
4.1 Structural Constraints 结构约束
Three types of binary relations
- one-to-one – 1:1
- one-to-many – 1:*
- many-to-many – :
4.2 EER Modeling
- ER modelling does not capture all the semantics of client’s domain, such as
- ‘ISA’
- ‘HASA’
- Enhanced ERmodels represent the above relationships
4.3 Step-by-Step Procedure for Conceptual design
- Identify entity types 识别实体类型
- Identify relationship types 确定关系类型
- Identify and associate attributes with entity or relationship types 识别属性并将其与实体或关系类型相关联
- Determine attribute domains 确定属性域
- Determine candidate, primary and alternate key attributes 确定候选、主键和备用键属性
- Consider use of enhanced modelling concepts (optional) 考虑使用EER(可选)
- Check model for redundancy 检查模型冗余
- Validate conceptual model against user transactions 根据用户事务验证概念模型
- Review conceptual data model with user 与用户一起回顾概念数据模型
4.4(Q) Brief explantation on an ontology and a database schema, and discuss one similarity between the two 简短介绍本体与 database schema,并且讨论相似之处
Anontology:
- Anontology is a model that clarifies and specifies a set of meanings in a formal language. 本体是一种用形式语言阐明和指定一组意义的模型
- Those meanings reflect the ontologist’s understanding of the target subject matter, regarding the kinds of things there are and how those things are related to each other. 这些意义反映了本体论者对目标主体的理解,关于存在的事物种类以及这些事物如何相互关联
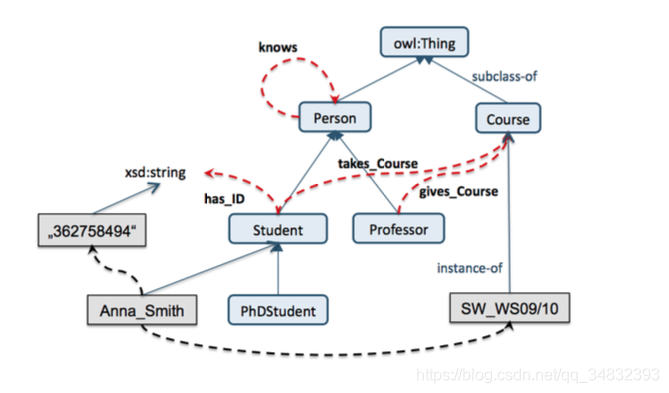
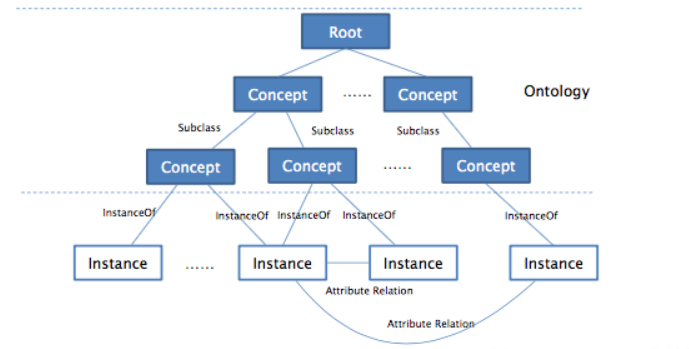
Database schema:
- A database schema defines the structure of a database in a formal language. 数据库模式用一种形式语言定义数据库的结构
- There are three kinds of database schemas: conceptual, logical and physical. 有三种数据库模式:概念模式、逻辑模式和物理模式
Similarity:
- At the conceptual level, both consist of set of type definitions expressed in a formal notation. 在概念级别上,两者都有一组用形式化符号表示的类型定义
5 Normalisation
5.1 Data Redundancy
- Major aim of relational database design is
- to group attributes into relations to minimize data redundancy 将属性分组到关系中以减少数据冗余
- to reduce file storage space required by base relations 减少基本关系所需的文件存储空间
- Data redundancy is undesirable because of the following anomalies 由于以下异常情况,数据冗余不可取
- ‘Insert’ anomalies 插入异常
- ‘Delete’ anomalies 删除异常
- ‘Update’ anomalies 更新异常
如果数据的插入、更新、删除操作不完整或不正确,就会产生数据冗余和异常,例如在插入一个新订单时,没有同时插入相关的订单明细,导致订单信息不完整或不准确。如果缺乏有效的数据约束和完整性检查机制,也会导致数据冗余和异常,例如没有设置外键约束,导致存在无效的关联数据。因此,在设计数据库时,需要考虑数据的完整性和一致性,采用合适的数据约束和完整性检查机制,避免数据冗余和异常的产生。
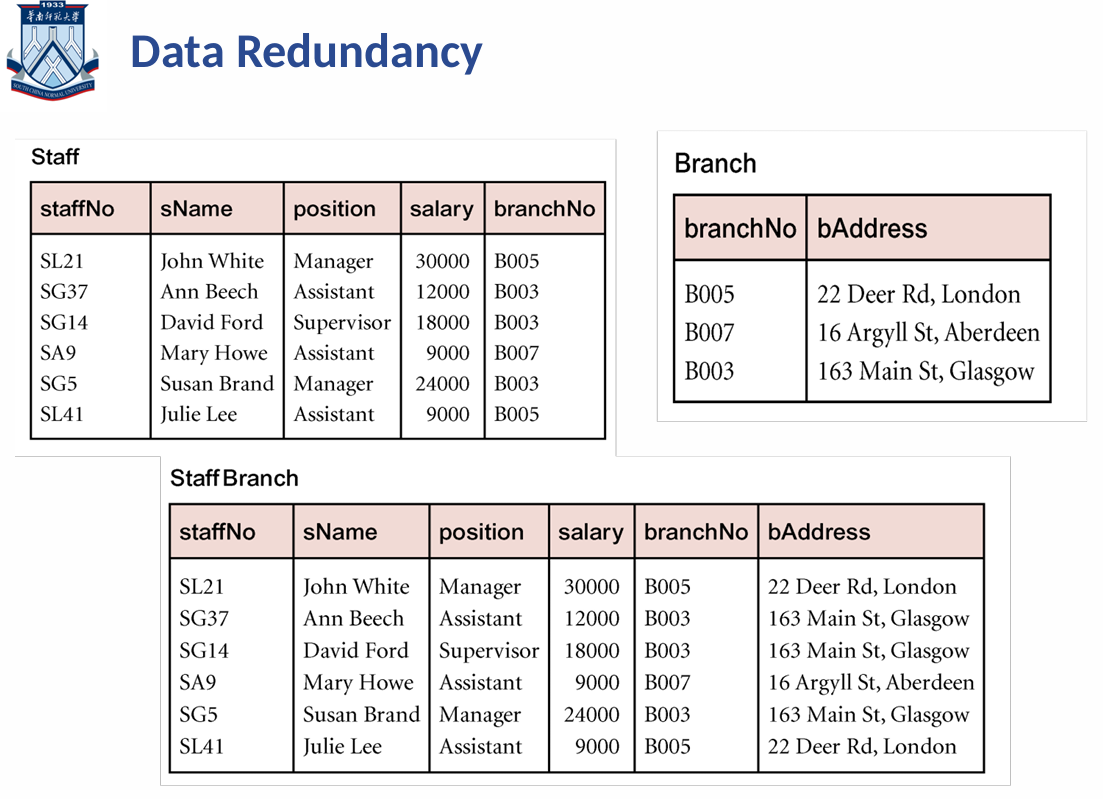
5.2 The reasons of why the insertion, deletion, and modification anomalies are considered bad
- Anomalies are considered to be bad in the sense that they create dirty data that would be incomplete and inconsistent. 因为它们会产生不完整和不一致的脏数据
- Moreover, improper insertion, deletion, or update operations will violate the integrity properties. 此外,不当的插入、删除、或更新操作将违反完整性属性
- Thus, the entire database would be inconsistent. 因此,整个数据库将是不一致的
5.3 The Process of Normalization
- 规范化依赖于主键和函数依赖性来分析关系。
- 它通常作为一系列步骤执行,每个步骤对应一个特定的正规形式。
- 随着规范化进程推进,关系在格式上变得更加严格,并且对更新异常也更不敏感。
- 要找出当前所使用的正规形式,并据此执行转换:
- 确认现有模型属于哪个正则形态
- 将关系转换到下一个高级正则形态,通过分解使其结构简单化
- 如果需要,可能还需进一步精炼关系以消除由分解导致的不良影响。
e.x., 在第一阶段(第一范式1NF),确保所有字段都是原子性质
接着如果满足第二阶段(第二范式2NF),就要去除部分函数依赖
然后再看是否能达到第三阶段(第三范式3NF),即移除传递函数依赖等
5.4 有关规范化的一个完整例子:
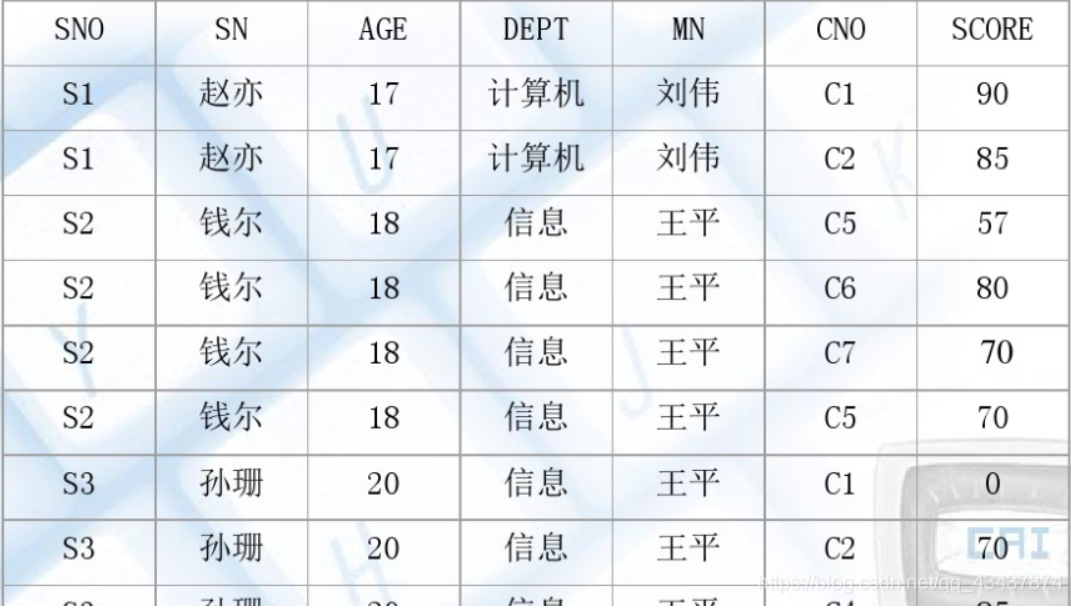
当前存在一个关系模式:SCD(Sno,Sname,Ssex,Sdept,Sdean,Cno,Cname,Grade),其中,SCD表示学生关系,对应的各属性依次为学号、姓名、性别、院系、系主任、课程号、课程名称和成绩。关系的主码为(Sno,Cno)。
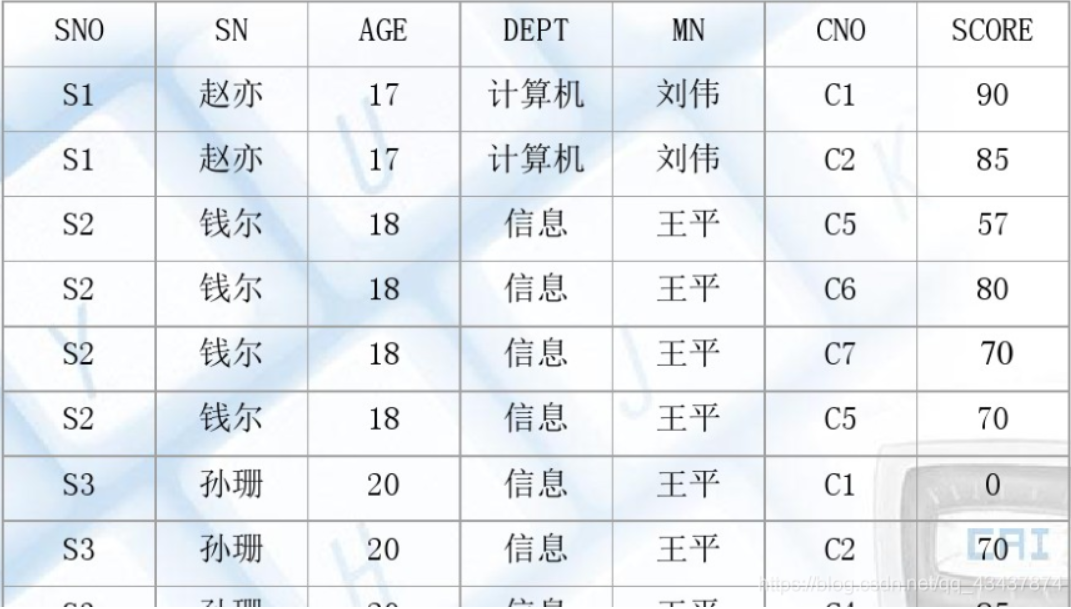
分析数据依赖
现在我们建立一个描述学校教务的数据库,该数据库涉及的对象包括学生的:
- 学号(Sno)
- 所在系(Sdept)
- 系主任姓名(Mname)
- 课程名(Cname)
- 成绩(Grade)
假设我们用一个单一的关系模式Student来表示,则该关系模式的属性集为: U ={ Sno,Sdept,Mname,Cname, Grade }
现实世界的已知事实(语义)告诉我们:
- 一个系有若干学生,但一个学生只属于一个系。
- 一个系只有一名主任。
- 一个学生可以选修多门课程,每门课程有若干学生选修。
- 每个学生所学的每门课程都有一个成绩。
从上述事实我们可以得到属性集U上的一组函数依赖F:F = { Sno→Sdept, Sdept→ Mname, (Sno,Cname)→Grade } 。即:学号决定所在系,所在系决定系主任名,学号和课程决定成绩。
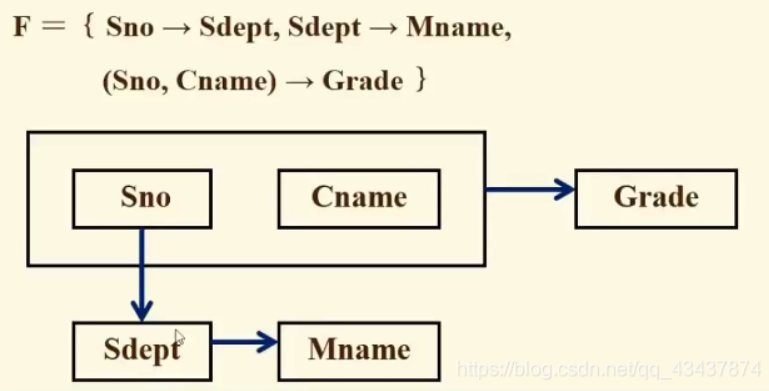
函数依赖的定义:
设关系模式R(U,F),U是属性全集,F是U上的函数依赖集,X和Y是U的子集,如果对于R(U)的任意一个可能的关系r,对于X的每一个具体值,Y都有唯一的具体值与之对应,则称X决定函数Y,或Y函数依赖于X,记作X→Y。我们称X为决定因素,Y为依赖因素。当Y不函数依赖于X时,记作:x-/->Y。当X→Y且Y→X时,则记作:X<–>Y。
1. 非平凡函数依赖与平凡函数依赖
在关系模式R(U)中,对于U的子集X和Y
如果X→Y,但Y不属于X,则称X→Y是非平凡的函数依赖
若X→Y,但Y 属于X,则称X→Y是平凡的函数依赖
在关系模式SC(Sno, Cno, Grade)中,(Sno, Cno)→ Grade,学号和课程决定成绩,但是成绩不属于学号或课程,则为非平凡的函数依赖。
(SnO,CNO)→CNO,学号和课程可以决定学号,学号也属于学号和课程,则为平凡的函数依赖,对于任一关系模式,平凡函数依赖都是必然成立的,它不反映新因此若不特别声明,我们总是讨论非平凡函数依赖。
2. 完全函数依赖与部分函数依赖
设关系模式R(U),U是属性全集,X和Y是U的子集,如果X→Y,并且对于X的任何一个真子集X’,都有X’-\ ->Y,则称Y对X完全函数依赖(Full Functional Dependency ) ,记作X-f>Y。
如果对X的某个真子集X’,有X’→Y,则称Y对X部分函数依赖(Partial Functional Dependency ) ,记作X-p->Y。
由定义知:
只有当决定因素是组合属性时,讨论部分函数依赖才有意义
当决定因素是单属性时,只能是完全函数依赖
3. 传递函数依赖和直接函数依赖
如果X->Y,Y->Z, 这时称Z对X传递函数依赖
如果Y→X,则X<–>Y,这时称Z对X直接函数依赖,而不是传递函数依赖
范式:
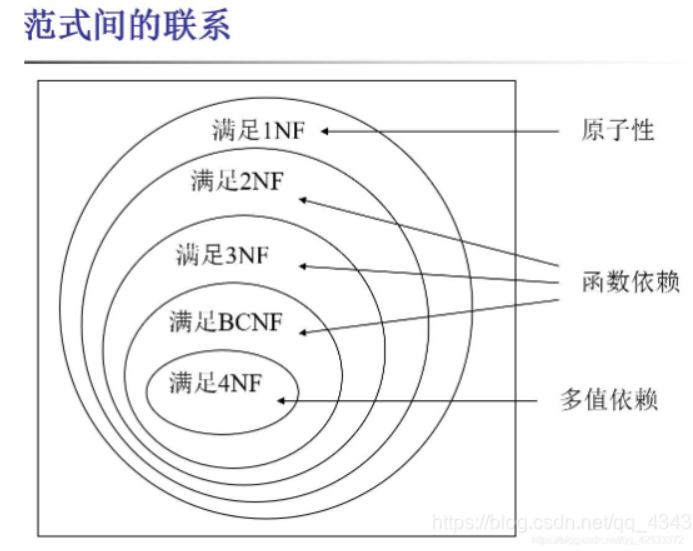
第一范式(First Normal Form)
第一范式是最基本的规范形式,即关系中每个属性都是不可再分的简单项。但是满足第一范式的关系模式并不一定是一个好的关系模式。
如果关系模式R,其所有的属性均为简单属性,即每个属性都城是不可再分的,则称R属于第一范式,简称1NF,记作R ∈1NF。
第二范式(Second Normal Form)
如果关系模式R∈ 1NF,且每个非主属性都完全函数依赖于R的每个关系键,则称R属于第二范式 ,简称2NF,记作R∈ 2NF。
在关系模式SCD中,SNO,CNO为主属性,AGE,DEPT,MN,MN,SCORE均为非主属性,经上述分析,存在非主属性对关系键的部分函数依赖,所以SCD不属于2NF。
第三范式(3rd Normal Form)
在以下情况下,表为第三范式:
它是第二范式
它不包含传递依赖项(非键属性通过另一个非键属性依赖于主键)
对于大多数表,第三范式通常就足够了,因为它避免了最常见的一种数据异常。建议您在实现之前将使用的大多数表转换为第三范式,因为在大多数情况下,这将实现数据库归一化概述中列出的归一化目标。
5.5(Q) The problem of spurious and how to prevent it 伪元组的问题与如何避免
- A spurious tuple is mainly a record in a database that gets created while two tables are joined badly.
伪元组主要是数据库两张连接不好的表产生的
- In a database, spurious tuples are formed while two tables are joined on attributes which are neither primary nor foreign keys.
在数据库中,当两个表连接在既不是主键也不是外键的属性上时,会形成虚假的元组
- To prevent spurious tuples, avoid joining relations that consist of matching attributes that are not primary or foreign key combinations as joining on such attributes may generate spurious tuples.
为了防止虚假的元组,避免有非主键或外键组合的匹配属性组成的连接关系
5.6(Q) The reasons for NULLs in a relation be avioded as much as possible
- NULLs should be avoided to avoid complexity in SELECT and UPDATE queries
为了避免 SELECT 和 UPDATE 的复杂度
- Furthermore, columns which have constraints like primary or foreign key constraints cannot contain a NULL value.
此外,具有主键约束和外键约束的列不能包含NULL值
6 Access Control
6.1 The Importance of Views & Privileges
- Inlarge organisations, DBMSs are used by a range of staff:
- directors, managers, analysts, engineers, personnel, secretarial, etc.
- Consequently, access to data in different tables may need to be controlled to:
- provide access to authorised users 向授权用户提供访问权限
- restrict access to unauthorised users 限制未授权用户访问
- enforce business rules or government regulations 执行业务规则或政府法规
- Views & privileges can help implement access control…
6.2 The meant of granting and revoking a priviledge
- Granting and revoking privileges is a task that you would perform when you want to allow or disallow users of the database to be able to reference data within the database as part of a security practice.
作为安全实践的一部分,当您希望允许或不允许数据库的用户能够引用数据库中的数据时,可以执行授予和撤销特权的任务。
- The GRANT privilege statement grants privileges on the database as a whole or on individual tables, views, sequences or procedures.
GRANT特权语句授予对整个数据库或单个表、视图、序列或过程的权限。
- It controls access to database objects, roles and DBMS resources.
它控制对数据库对象、角色和DBMS资源的访问。
- The REVOKE statement revokes privileges. It removes database privileges or role access granted to the specified users, groups, role or PUBLIC.
REVOKE语句撤销特权。它删除授予指定用户、组、角色或PUBLIC的数据库特权或角色访问权限。
- You cannot revoke privileges granted by other users.
你不能撤销其他用户授予的权限。
6.3 SQL’s Access Control Model
- Access Control in SQL is similar to multi-user operating systems (e.g., Unix, Windows, …). SQL 的访问控制类似于多用户操作系统
- A user supplies an Authorisation Id and password to the DBMS. 用户向 DBMS 提供授权 ID 与密码
- The DBMS opensasession for the user. DBMS 为用户打开一个通话
- The DBMS runs SQL statements on behalf of the user. DBMS 代表用户运行 SQL 语句
- The user becomes the owner of any objects they create. 用户成为他们创造的任何对象的所有者
- Bydefault, only the owner may access their objects. 默认情况下,只有所有者可以访问他们的对象
- Theowner maygrant andrevoke access privileges to other users. 所有者可以授予和撤销其他用户的访问权限
6.4(Q) The difference between discretionary and mandatory access control 自由裁量访问控制和强制访问控制的区别
- In mandatory access control, the system and not the users, determines which subjects can access specific data objects.
在强制访问控制中,是系统不是用户决定了哪些主体可以访问特定的对象
- Discretionary access control is different from mandatory access control because the owner of the data object specifies which subjects can access the data object.
在自由裁量访问控制中,是数据对象所有者决定哪些主体可以访问数据对象
6.5(Q) The meant of row-level access control
- Row level access control refers to the practice of controlling access to data in a database by row, so that users are only able to access the data they are authorized for. 行级访问控制是指按行控制对数据库中数据的访问,以便用户只能访问他们被授权的数据
- This contrasts with database-level or table-level access control, which controls access to entire databases or tables, respectively. 这与数据库级或表级访问控制形成对比,后者分别控制对整个数据库或表的访问
7 Transaction Management
7.1 Transaction Management Overview
- Objective
- schedule queries from multiple simultaneous users efficiently 高效的调度来自多个用户的查询
- keep the database in a consistent state 保持数据库处于一致状态
- Transaction management involves
- performing “logical units of work” (definition of transactions) 执行逻辑工作单元
- controlling concurrency – stop user tasks interfering 控制并发
- resolving conflicts – e.g., simultaneous update attempts 解决冲突
- recovering from errors – restore DB to consistent state 从错误中恢复
7.2 The “ACID” Requirements For a Transaction
- Atomicity – each unit of work is indivisible; “all-or-nothing” (transactions that don’t complete must be undone or “rolled-back”)
- Consistency – a transaction transforms the database from one consistent state into another (intermediates may be inconsistent)
- Isolation – each transaction effectively executes independently – one transaction should not see the inconsistent/incomplete state of another transaction
- Durability – once a transaction is complete, its effects cannot be undone or lost (it can only be “undone” with a compensating transaction)
7.3(Q) Discuss the atomicity, durability, isolation, and consistency preservation properties of a database transaction.
- Atomicity is a property that ensures that a database follows the all or nothing rule. In other words, the database considers all transaction operations as one whole unit or atom.
- Consistency is a property ensuring that only valid data following all rules and constraints is written in the database. When a transaction results in invalid data, the database reverts to its previous state, which abides by all customary rules and constraints.
- Isolation is a property that guarantees the individuality of each transaction, and prevents them from being affected from other transactions. It ensures that transactions are securely and independently processed at the same time without interference, but it does not ensure the order of transactions.
- Durability is a property that enforces completed transactions, guaranteeing that once each one of them has been committed, it will remain in the system even in case of subsequent failures. These failures include transaction failures and catastrophic failures.
7.4 Concurrent Transections - The Lost Update Problem
- Suppose anaccount holds £100. If T1 deposits £100 and T2 withdraws £10, the new balance should be £190. With concurrent transactions, we could get:
- T1: UPDATE Account SET Balance = Balance + 100;
- T2: UPDATEAccount SET Balance = Balance - 10;
7.5 Serialising Transactions 连载事物
- One solution would be to serialise all transactions:
- make first transaction finish before next one starts
- However, this would not be efficient on multi-user systems
- A non-serial schedule interleaves operations from a set of concurrent transactions 非串行调度将来自一组的并发事务操作穿插在一起
- should produce the same results as some serial schedule
- Only need to schedule transactions
- that refer to the same data items and perform a mixture of writes and reads 它们引用相同的数据项,并混合执行写和读操作
- some transactions might benefit from running simultaneously (e.g., if they both read the same tables) 有些事务可能会从同时运行中受益(例如,如果它们都读取相同的表)
7.6(Q) What is a serial schedule? What is a serialisable schedule? Why is a serial schedule considered correct? Why is a serialisable schedule considered correct?
- Aserial schedule is a type of schedule where one transaction is executed completely before starting another transaction. 串行调度是一种调度类型,其中开始另一个事务之前一个事物会被完全执行
- A serial schedule always gives the correct result. Consider two transactions T1 and T2 which perform some operations. If it has no interleaving of operations, then there are two possible outcomes: either execute all of T1 operations, which were followed by T2 operations. 连续进度表总是给出正确的结果。考虑两个执行一些操作的事物T1和T2,如果它没有交错的操作,那么有两种可能的结果:执行所有的T1操作,然后是T2操作
7.7(Q) Discuss the actions taken by the read item, modify item and write item operations on adatabase
- The read_item operation reads a data item from storage to main memory
- The modify_item operation changes the value of item in the main memory
- The write_item operation writes the modified value from memory to storage
7.8(Q) Define the violations caused by each of the following: (a) dirty read, and (b) phantoms. 脏读取 幻象
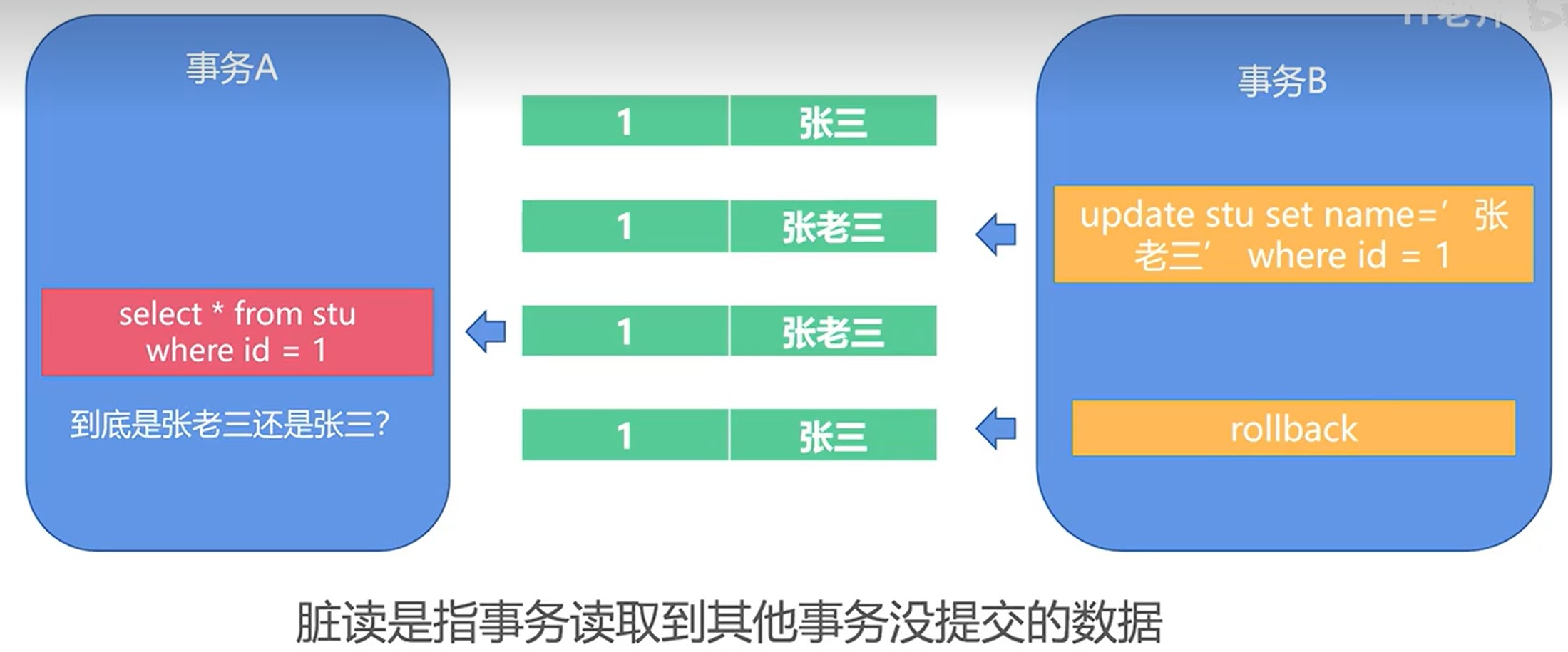
脏读指读取到其他事务正在处理的未提交数据
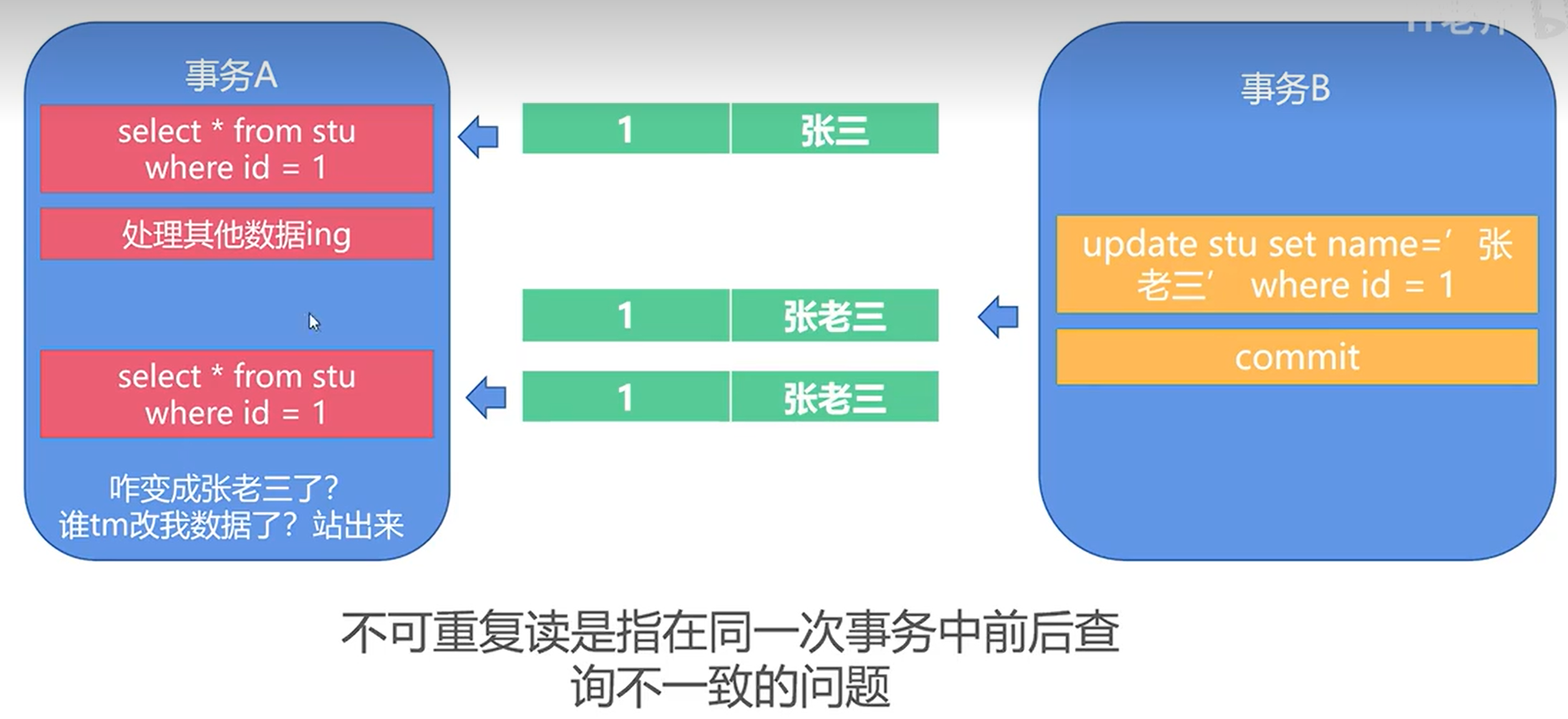
不可重复读是指并发更新时,另一个事务前后查询相同数据时的数据不符合预期
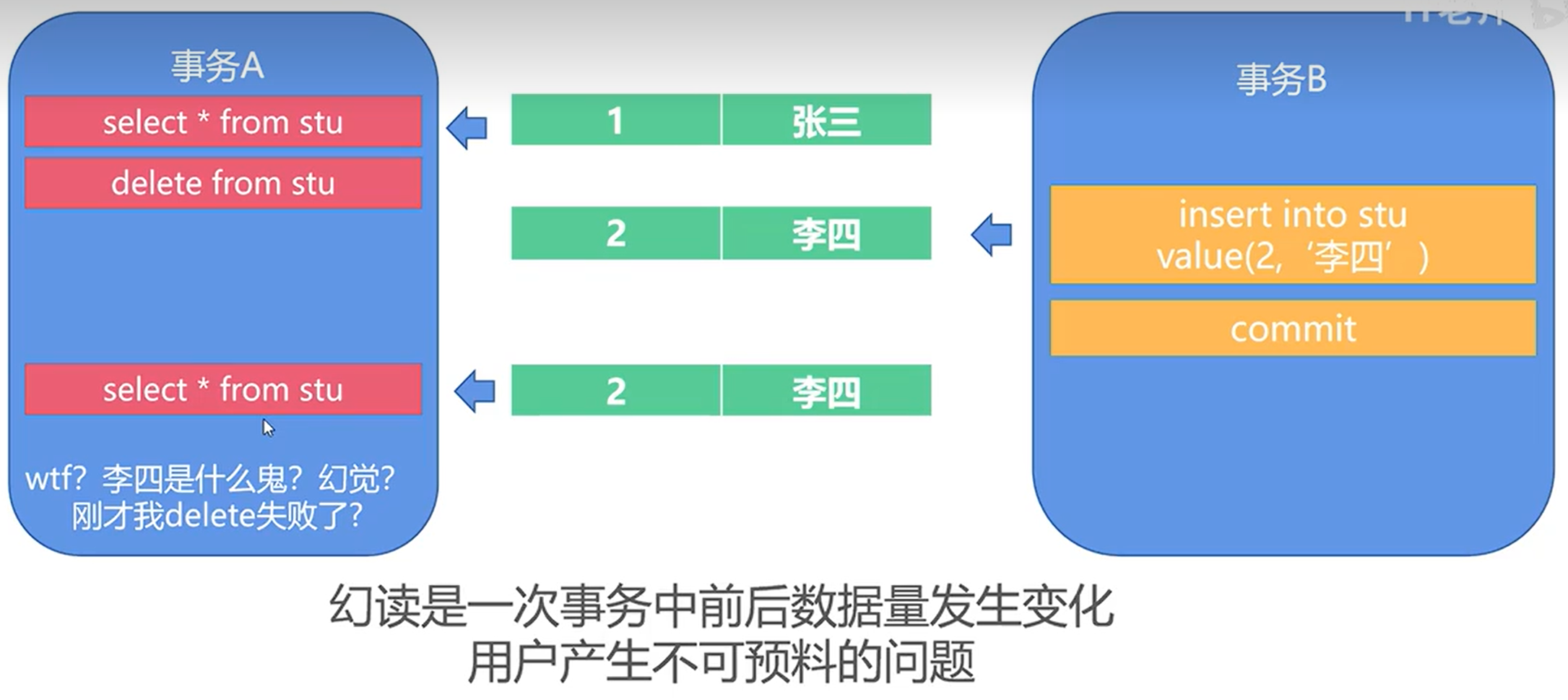
幻读是指并发新增、删除这种会产生数量变化的操作时,另一个事务查询相同数据时的不符合预期
- A dirty read occurs if one transaction reads data that has been modified by another transaction.
- This results in a violation of transaction isolation, if the transaction that modified the data is rolled back.
- A phantom read occurs when a transaction retrieves a set of rows twice
- and new rows are inserted or removed from that set by another transaction that is committed in between.
8 File organisation
8.1 Data storage
- DBMS has to store data somewhere
- Choices:
- Main memory
- Expensive – compared to secondary and tertiary storage 昂贵
- Fast – in memory operations are fast 快速
- Volatile – not possible to save data from one run to its next 易失
- Used for storing current data (10 GBs) 存储当前数据
- Secondary storage (hard disk)
- Less expensive – compared to main memory
- Slower – compared to main memory, faster compared to tapes
- Persistent – data from one run can be saved to the disk to be used in the next run 持续的
- Usedforstoring the database (10 TBs, 2016)
- Tertiary storage (tapes)
- Cheapest
- Slowest – sequential data access
- Used for data archives (Sony 185 TB tapes, 2014) 用于数据归档
- Main memory
8.2(Q) Two differences between primary and secondary storage
- Primary storage is the computer’s main memory and stores data temporarily.Secondary storage is external memory and saves data permanently
- Data stored in primary storage can be directly accessed by the CPU, which cannot be accessed in secondary storage
8.3 DBMS Stores Data on Hard Disks
- This means that data needs to be
- read from the hard disk into memory (RAM)
- written from the memory onto the hard disk
- Because I/O disk operations are slow query performance depends upon how data is stored on hard disks 由于磁盘I/O操作较慢,查询性能取决于数据以何种方式存储在硬盘上
- The lowest component of the DBMS performs storage management activities DBMS的最底层组件执行存储管理活动
- Other DBMS components need not know how these low level activities are performed 其它DBMS组件不需要知道这些低级活动是如何执行的
8.4 Basics of Data Storage on Hard Disk
A disk is organized into a number of blocks or pages

A. Track 磁道 B. Sector C. Block D. Cluster E. Page
- A page is the unit of exchange between the disk and the main memory 页是磁盘和主存交换的单位
- A collection of pages is known as a file 页面的集合称为文件
- DBMS stores data in one or more files on the hard disk DBMS将数据存储在硬盘的一个或多个文件中
8.5(Q) Two techniques for allocating file blocks on a disk in detail
Two techniques for allocating file blocks on disk are: contiguous file allocation and linked file allocation. 连续文件分配和链接文件分配
- In contiguous file allocation, the block is allocated in such a manner that all the allocated blocks in the hard disk are adjacent. Assuming a file needs n number of blocks in the disk and the file begins with a block at position x, the next blocks to be assigned to it will be x + 1, x + 2, x + 3, …, x + n–1 so that they are in a contiguous manner.
- Inlinked file allocation, the file which we store on the hard disk is stored in a scattered manner according to the space available on the hard disk. To rememberthe blocks that belong to the same file, the linked file allocation technique uses pointers to point to the next block of the same file. Therefore, along with the entry of each file each block also stores the pointer to the next block.
8.6 Indexing
- Index – a data structure that allows the DBMS to locate particular records in a file more quickly
- Very similar to the index at the end of a book to locate various topics covered in the book
- Types of Index
- Primary index – one primary index per file
- Clustering index – one clustering index per file– data file is ordered on a non-key field and the index file is built on that non-key field
- Secondary index – many secondary indexes per file
- Sparse index – has only some of the search key values in the file
- Dense index – has an index corresponding to every search key value in the file
8.7 Explain how double buffering improves block access time
With double buffers, when the CPU is processing the current block of data in buffer 1, it can also retrieve the next block into buffer 2 at the same time. When processing of buffer 1 is done, the CPU can then move on to the next block in buffer 2 immediately without waiting.
9 Database security
9.1 CommonSecurity Measures
- Authorization – privileges, views
- Authentication – passwords
- Verification – digital signatures/certificates
- Encryption – public key / private key, secure sockets
- Integrity – IEF (Integrity Enhancement Features), transactions
- Backups – offsite backups, journaling, log files
- RAID(Redundant Array of Independent Discs) discs – data duplication, “hot swap” discs
- Physical – data centres, alarms, guards, UPS
- Logical – firewalls, net proxies
9.2(Q) What is label security? How does an administrator enforce it?
Rows of data are labelled to indicate the level and nature of their sensitivity. A label on a row of data specifies the sensitivity of the information in the row and explicitly defines the criteria that must be met for a user to access that row. An administrator enforces label security by implementing the following process:
- Create the label security policy container 创建标签安全策略容器
- Create data labels for the label security policy 为标签数据安全创建数据标签
- Authorise users for the label security policy 授权用户使用标签安全策略
- Grant privileges to users and trusted stored program units 授予用户和受信用的储存进程单元特权
9.3(Q) What is flow control as a security measure? What types of flow control exists?
Flow controls, most commonly, use a concept of security classes, where transmission of data is blocked if the receiver has a security level lower than the sender. There are two types of flow control:
流控制通常使用安全类的概念,如果接收方的安全级别低于发送方,则数据传输将被阻止
- Explicit flows, consequences of assignments 显式流,赋值的结果
- Implicit flows, generated by conditions 隐式流,由条件产生
10 DB Web technologies
10.1 Basics of WWW
- The Web is a very large client-server system
- Connected through routers and switches
- Communicating with TCP/IP protocol
- With no centralised control 没有集中控制
- Servers publish pages at URLs
- Clients request pages by specifying the URLs
- Pages are transferred on the Web using HTTP protocol
- Each HTTP interaction is independent 每个HTTP交互都是独立的
- No concept of a state or session 没有状态和会话的概念
10.2 1990’s Client-Server DBMS Architecture
- Example: A high street travel agency
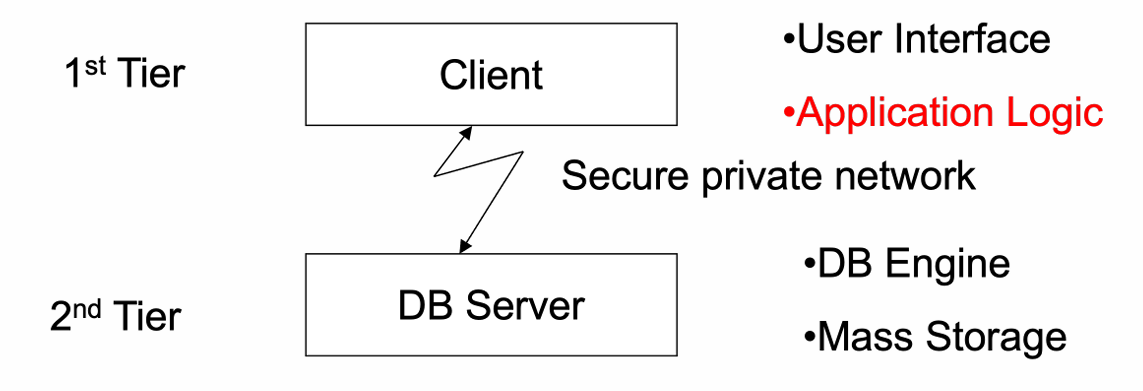
- Application/business code on client machine– “fat client” 胖客户机
- Proprietary software– expensive to maintain & update
10.3 From 1995: Three-Tier Architecture
- Example: A web-based bookstore. e.g., amazon.co.uk
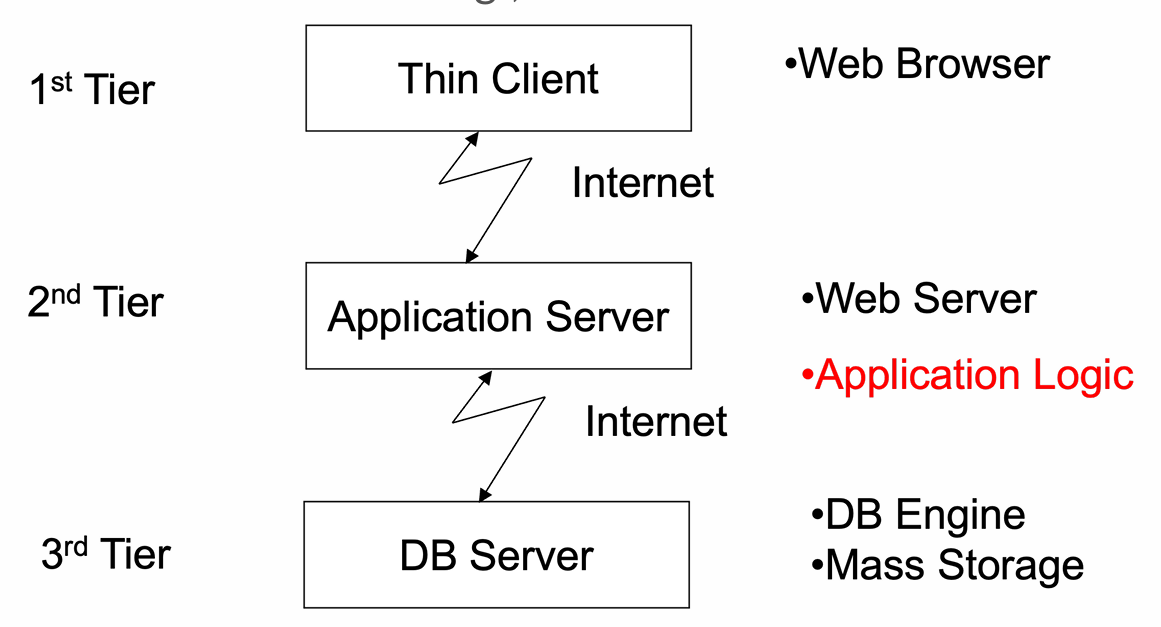
- All application/business code off client, onto server 所有应用/商业代码从客户机转到应用服务器
10.4 Characteristics of Three-Tier Architecture
- Advantages:
- Platform independence – web browsers for every PC 平台独立性
- Cheap graphical user interface – potential for innovation 廉价GUI界面
- Simplicity – easier to upgrade & scale 简化
- Disadvantages:
- Costly to maintain server – poor development tools
- Less secure (hackers, etc.)
- Less reliable (packet loss)
- Stateless – no built-in support for transactions 无状态,没有内置事务支持
- Scaling limitations – size of data and No. of users 扩展限制
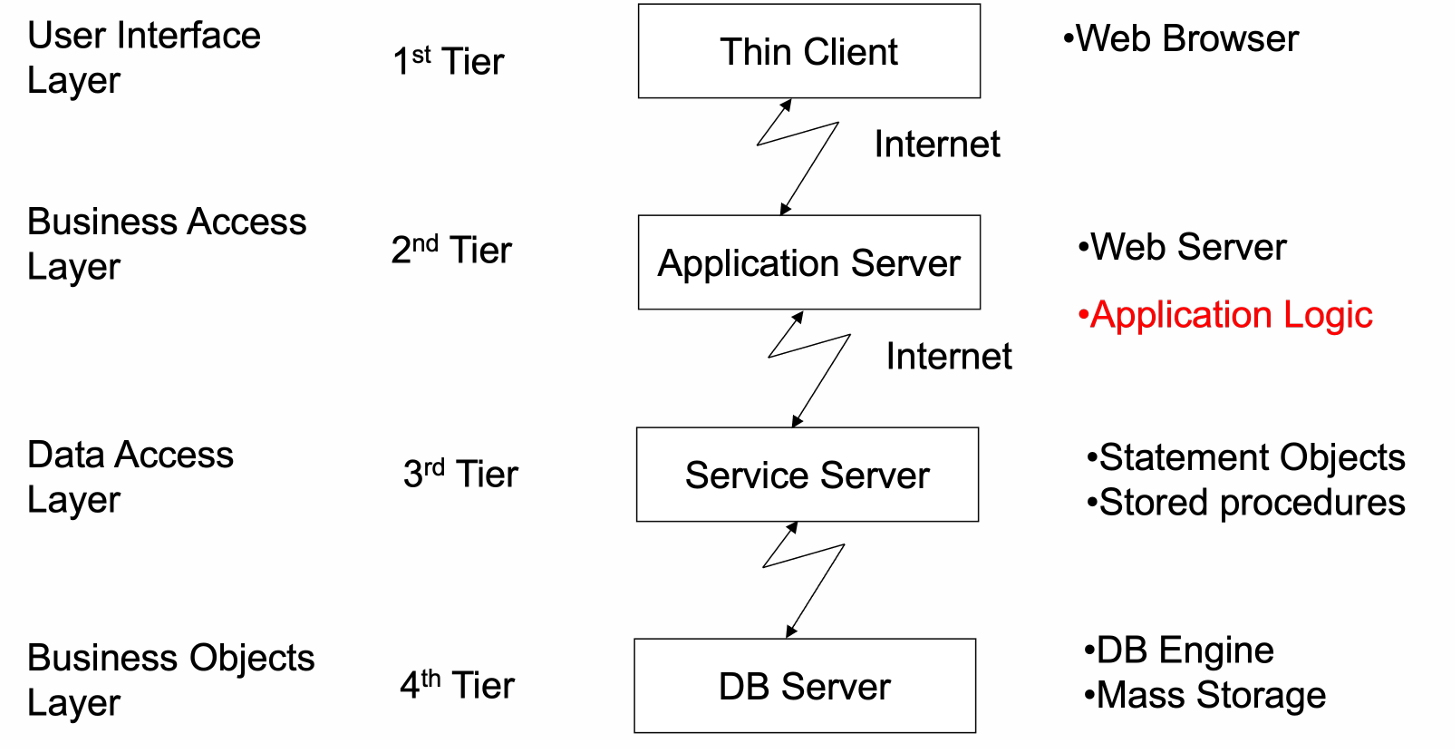
10.5 University Architecture
10.6(Q) Discuss three types of arrays in PHP
An array in PHP is actually an ordered map. A map is a type that associates values to keys. This type is optimised for several difference users; it can be treated as an array, a list, a hash table, a dictionary, etc. In PHP, the three types of arrays are: (a) indexed arrays, (b) associative arrays, and (c) multidimensional arrays.
- An indexed array is an array with a numeric key. It stores each array element with a numeric index.
- An associative array is an array where each key has its own specific value. The keys assigned to values can be arbitrary and user defined strings.
- A multidimensional array is an array containing one or more arrays within itself. Each element in the array can also be an array and each element in the sub-array can be an array or further contain array within itself.
10.7(Q) What are PHP auto-global-variables?
PHP auto-global-variables are built-in variables that are always available in all scopes. Some predefined variables in PHP are super globals, which means that they are always accessible, regardless of scope, and you can access them from any function, class or file without having to do anything special.
11. NoSQL
11.1 Relational V.S. NoSQL
NoSQL (“Not Only SQL”)
- Uses Clusters 使用集群:
- Distribute the Data via Replication & Sharding 通过复制和分片分发数据
- Distribute the Processing Across Multiple Nodes in a Cluster 将处理分布在集群的多个集点上
- Uses Replication to provide 使用复制提供
- Redundancy 冗余
- High Availability 高可用性
- Parallel Processing 并行处理
- VERY Horizontally scalable 非常水平扩展

11.2 CAP theorem
In theoretical computer science, the CAP theorem states that any distributed data store can provide only two of the following three guarantees: consistency, availability, and partition tolerance.
Consistency guarantees that every read receives the most recent write or an error.
Availability guarantees that every request receives a non-error response, without the guarantee that it contains the most recent write.
Partition tolerance guarantees that the system continues to operate despite an arbitrary number of messages being dropped or delayed by the network between nodes.
11.3(Q) Which of the three properties (consistency, availability, partition tolerance) are most important in NoSQL systems?
In a networked NoSQL system, partition tolerance is a must. Network partitions and dropped or delayed messages are a fact in these networked shared-data systems and it must be handled appropriately.
Consequently, system designers must choose between consistency and availability. A NoSQL system that prioritises availability over consistency can respond with possibly stale data.
In contrast, a NoSQL system that prioritises consistency over availability can respond with the latest updated data. [1 mark] The system can be distributed across multiple servers and is designed to operate reliably even in the presence of network partitions.
So, the partition tolerance and consistency properties are most important in NoSQL systems that require immediate consistency.
11.4(Q) What are the similarities and differences between consistency in CAP versus consistency in ACID?
In a distributed database system, the term consistency implies that different nodes or servers respond with the same data to the same request. 在分布式数据库系统中,一致性意味着不同的节点或服务器对相同的请求使用相同的数据进行响应。
In a relational database system, the term consistency implies that the database enforces rules about its f ields and the relationship between fields. 在关系数据库系统中,术语一致性意味着数据库强制执行关于其字段和字段之间关系的规则。
12 Extensible Markup Language 可拓展标记语言
12.1 Structured, Semi-structured, and Unstructured Data
- Structured data
- Represented in a strict format (schema)
- Example: information stored in databases
- Semi-structured data
- Has a certain structure
- Not all information collected will have identical structure
- Unstructured data
- Limited indication of the of data document that contains information embedded within it
12.2(Q) What are the differences between structured, semi-structured and unstructured data?
- Structured data can be displayed in rows, columns and relational databases. Unstructured data cannot be displayed in rows, columns and relational databases. 结构化数据可以以行、列和关系数据库的形式显示.不能在行、列和关系数据库中显示非结构化数据。
- Structured data is comprised of numbers, dates and strings. Unstructured data is comprised of images, audio, video, word processing files, emails, spreadsheets, etc. 结构化数据由数字、日期和字符串组成。非结构化数据包括图像、音频、视频、文字处理文件、电子邮件、电子表格等。
- Incontrast to structured data, which requires less storage, unstructured data requires more storage. Also, it is more difficult to manage and protect unstructured data with legacy solutions. 结构化数据需要较少的存储空间,而非结构化数据需要更多的存储空间。此外,使用遗留解决方案管理和保护非结构化数据更加困难。
- Semi-structured data is information that doesn’t consist of structured data but still has some structure to it. It includes key-value stores and graph databases. 半结构化数据是指不包含结构化数据但仍具有某种结构的信息。它包括键值存储和图形数据库
12.3 XML Hierarchical (Tree) Data Model
- Elements and attributes
- Complex elements
- Simple elements
- XMLtagnames
