Html: <title>Header</title> Name: title Text: Header
2.2BeautifulSoup 遍历标签
使用 recursiveChildGenerator() 方法,可以遍历 HTML 文档
1 2 3 4 5 6 7 8 9 10
withopen("index.html", "r") as f:
contents = f.read()
soup = BeautifulSoup(contents, 'lxml')
for n in soup.recursiveChildGenerator(): if n.name: print(n.name)
1 2 3 4 5 6 7 8 9 10 11 12 13 14
html head title meta body h2 ul li li li li li p p
3BeautifulSoup 元素关系
3.1 子元素
使用 children 属性,我们可以获得一个标签的子级
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
from bs4 import BeautifulSoup
withopen("index.html", "r") as f:
contents = f.read()
soup = BeautifulSoup(contents, 'lxml')
root = soup.html root1 = soup.body
root_childs = [e.name for e in root.children if e.name isnotNone] # 检索 html 标签的子级,将它们放到一个列表中 root_childs1 = [e.name for e in root1.children if e.name isnotNone] # 检索 body 标签的子级,将它们放到一个列表中
print(root_childs) print(root_childs1)
1 2
['head', 'body'] ['h2', 'ul', 'p', 'p']
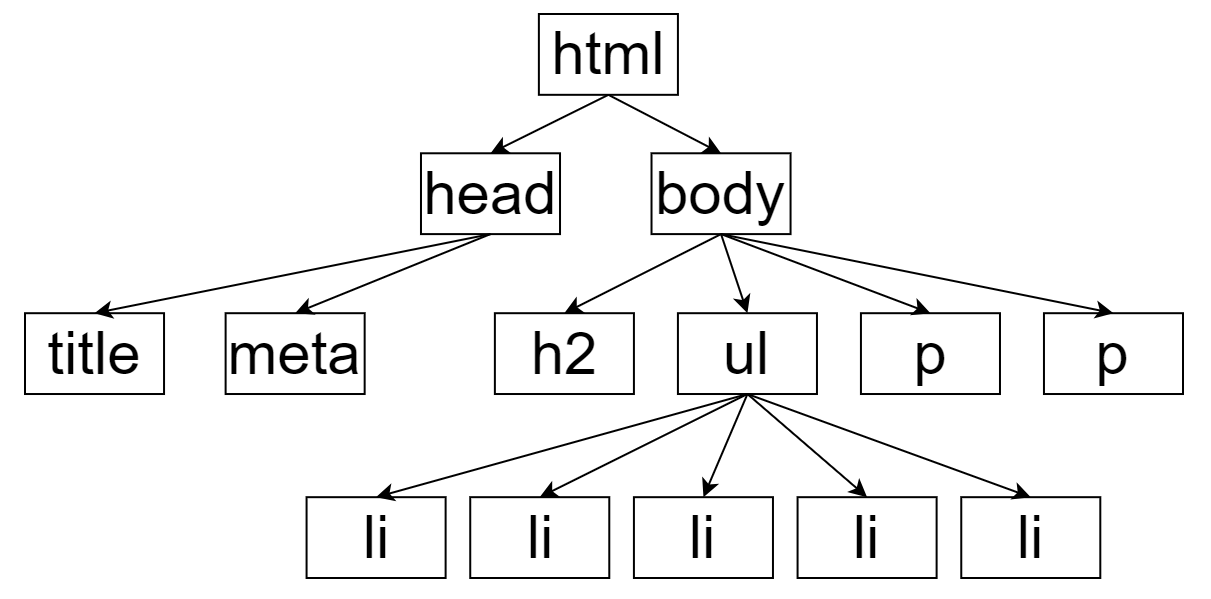
html 标记的子级有 head 和 body ,而 body 的子级有 h2,ul,p,p,这就是它们的子级关系,即“我子级的子级不是我的子级”
整体关系如下:
3.2 后继元素
使用 descendants 属性,我们可以获得标签的所有后代
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
from bs4 import BeautifulSoup
withopen("index.html", "r") as f:
contents = f.read()
soup = BeautifulSoup(contents, 'lxml')
root = soup.html root1 = soup.body
root_childs = [e.name for e in root.descendants if e.name isnotNone] # 检索 html 标签的后代,将它们放到一个列表中 root_childs1 = [e.name for e in root1.descendants if e.name isnotNone] # 检索 body 标签的后代,将它们放到一个列表中
<!DOCTYPE html> <html> <head> <title> Header </title> <meta charset="utf-8"/> </head> <body> <h2> Operating systems </h2> <ul id="mylist" style="width:150px"> <li> Solaris </li> <li> FreeBSD </li> <li> Debian </li> <li> NetBSD </li> <li> Windows </li> </ul> <p> FreeBSD is an advanced computer operating system used to power modern servers, desktops, and embedded platforms. </p> <p> Debian is a Unix-like computer operating system that is composed entirely of free software. </p> </body> </html>
4.2 get_text() 方法
如果只想得到 tag 中包含的 text 内容,那么可以调用 get_text() 方法,这个方法获取到 tag 中所有的 text 内容,包括子孙中的文本内容。
1 2 3 4 5 6 7 8 9 10 11
from bs4 import BeautifulSoup
withopen("index.html", "r") as f:
contents = f.read()
soup = BeautifulSoup(contents, 'lxml')
text_in_body = soup.body.get_text()
print(text_in_body)
1 2 3 4 5 6 7 8 9 10 11 12
Operating systems Solaris FreeBSD Debian NetBSD Windows FreeBSD is an advanced computer operating system used to power modern servers, desktops, and embedded platforms.
Debian is a Unix-like computer operating system that is composed entirely of free software.
5 查找
5.1 根据 id 进行查找
通过 find() 方法,我们可以通过各种方式(包括元素 id)查找元素
1 2 3 4 5 6 7 8 9
withopen("index.html", "r") as f:
contents = f.read()
soup = BeautifulSoup(contents, 'lxml')
n = soup.find("ul", id = 'mylist') # n = soup.find("ul", attrs = {'id' : 'mylist'}) # 执行相同任务的另一种方法 print(n)
for n in soup.find_all("li"): print("{0}: {1}".format(n.name, n.text))
1 2 3 4 5
li: Solaris li: FreeBSD li: Debian li: NetBSD li: Windows
5.2.2 多名称查找
find_all() 方法填入要查找的元素名称的列表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
from bs4 import BeautifulSoup
withopen("index.html", "r") as f:
contents = f.read()
soup = BeautifulSoup(contents, 'lxml')
tags = soup.find_all(['h2', 'p'])
for n in tags: print(" ".join(n.text.split())) # 想想看这里为什么用 (" ".join(n.text.split())) # 可以尝试先用 n.text ,再用 n.text.split() ,然后用 " ".join(n.text.split()) # 看看分别会发生什么
1 2 3
Operating systems FreeBSD is an advanced computer operating system used to power modern servers, desktops, and embedded platforms. Debian is a Unix-like computer operating system that is composed entirely of free software.
<!DOCTYPE html> <html> <head> <title> Header </title> <meta charset="utf-8"/> </head> <body> <h2> Operating systems </h2> <ul id="mylist" style="width:150px"> <li> OpenBSD </li> <li> FreeBSD </li> <li> Debian </li> <li> NetBSD </li> <li> Windows </li> </ul> <p> FreeBSD is an advanced computer operating system used to power modern servers, desktops, and embedded platforms. </p> <p> Debian is a Unix-like computer operating system that is composed entirely of free software. </p> </body> </html>
<body> <h2> Operating systems </h2> <ul id="mylist" style="width:150px"> <li> FreeBSD </li> <li> Debian </li> <li> NetBSD </li> <li> Windows </li> </ul> <p> FreeBSD is an advanced computer operating system used to power modern servers, desktops, and embedded platforms. </p> <p> Debian is a Unix-like computer operating system that is composed entirely of free software. </p> </body>